Abstract
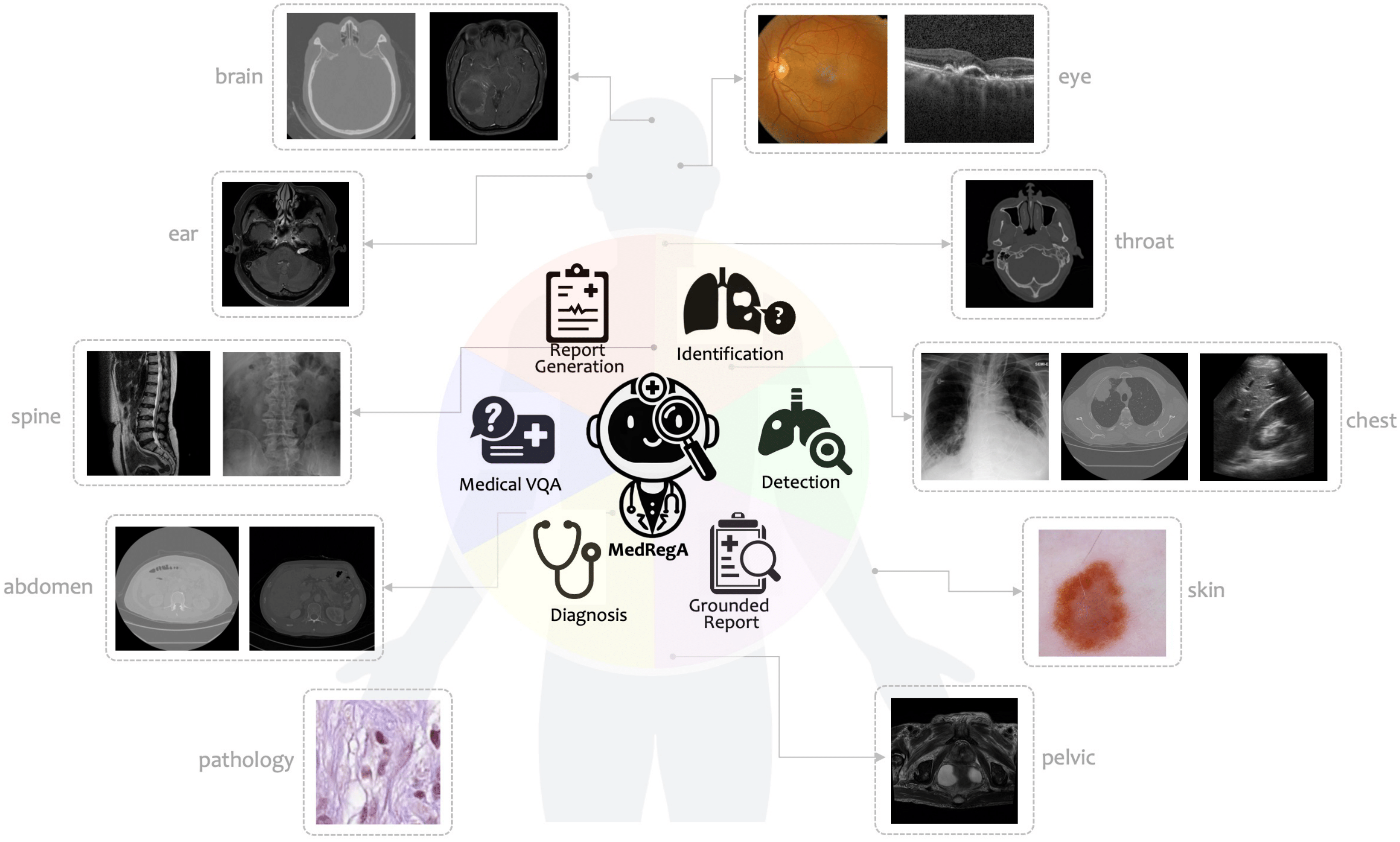
Several medical Multimodal Large Languange Models (MLLMs) have been developed to address tasks involving visual images with textual instructions across various medical modalities, achieving impressive results. Most current medical generalist models are region-agnostic, treating the entire image as a holistic representation. However, they struggle to identify which specific regions they are focusing on when generating a sentence. To mimic the behavior of doctors, who typically begin by reviewing the entire image before concentrating on specific regions for a thorough evaluation, we aim to enhance the capability of medical MLLMs in understanding anatomical regions within entire medical scans.
To achieve it, we first formulate Region-Centric tasks and construct a large-scale dataset, MedRegInstruct, to incorporate regional information into training. Combining our collected dataset with other medical multimodal corpora for training, we propose a Region-Aware medical MLLM, MedRegA, which is the first bilingual generalist medical AI system to simultaneously handle image-level and region-level medical vision-language tasks across a broad range of modalities. Our MedRegA not only enables three region-centric tasks, but also achieves the best performance for visual question answering, report generation and medical image classification over 8 modalities, showcasing significant versatility. Experiments demonstrate that our model can not only accomplish powerful performance across various medical vision-language tasks in bilingual settings, but also recognize and detect structures in multimodal medical scans, boosting the interpretability and user interactivity of medical MLLMs.
MedRegA on General Medical Tasks
English Report Generation
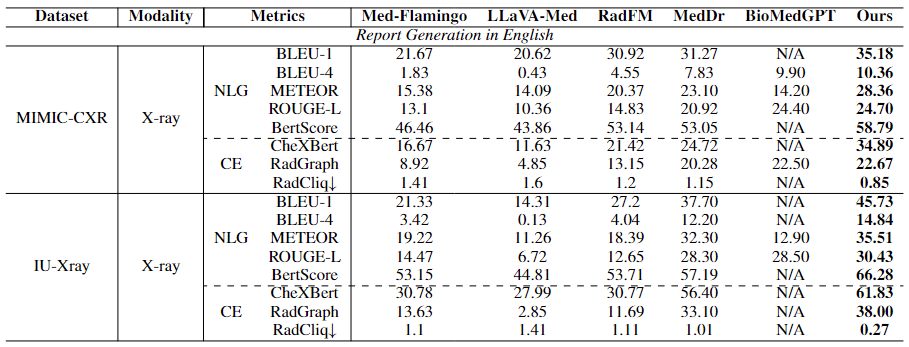
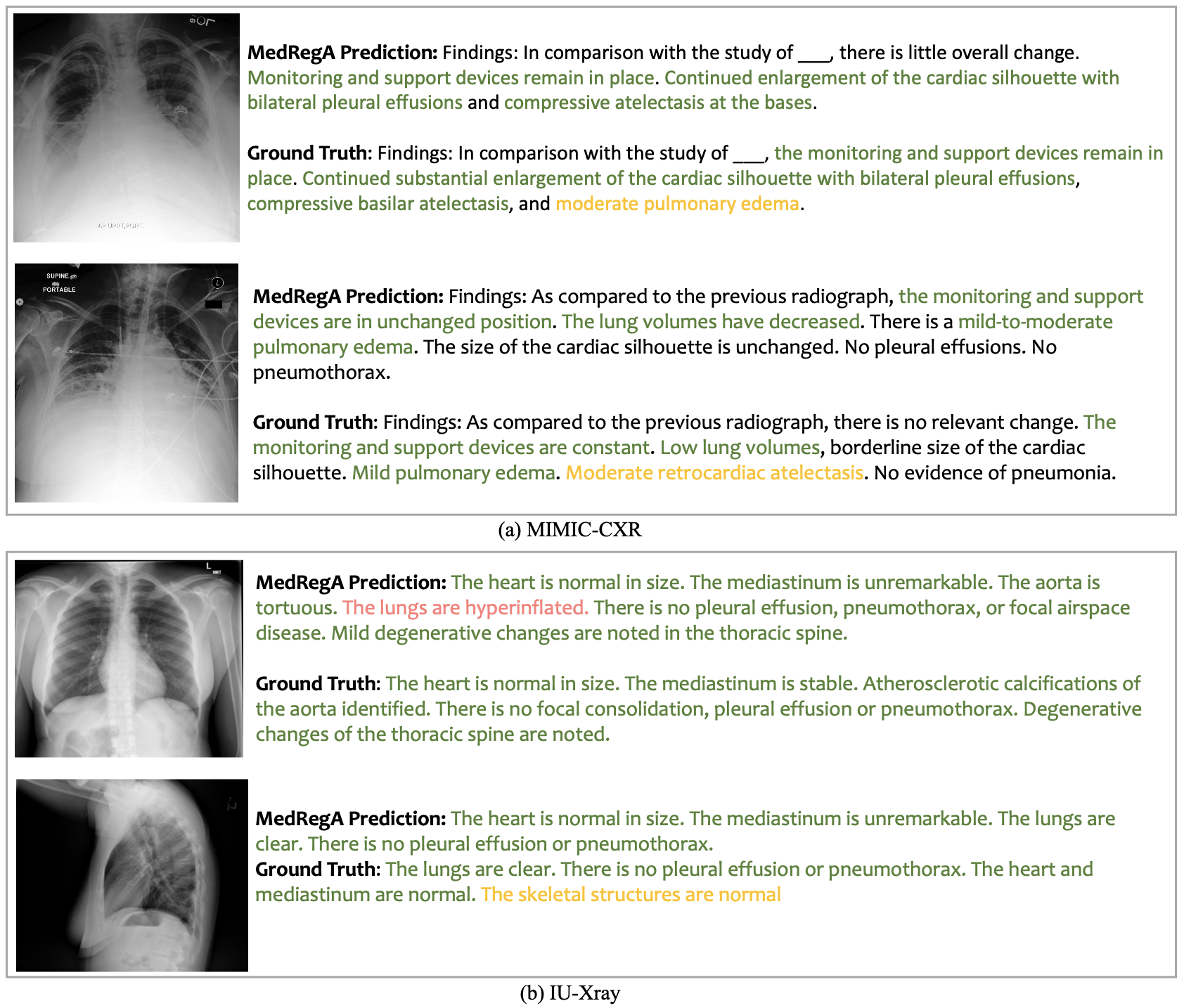
Medical Report Generation task requires the model to generate a detailed report based on the provided medical scan. For English report generation, we evaluate our model on the report generation task for chest X-ray datasets MIMIC-CXR and IU-Xray.
Chinese Report Generation
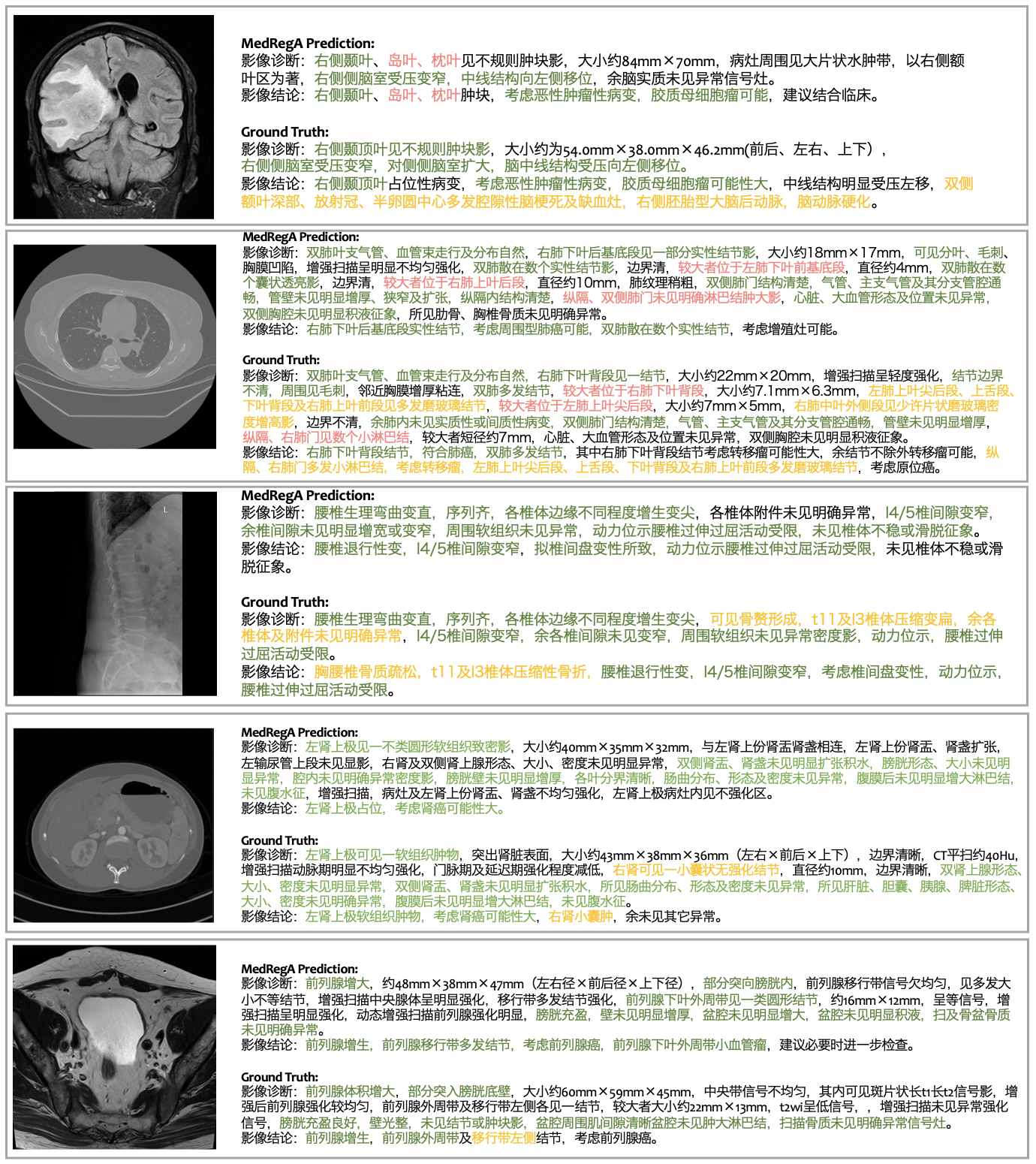
To evaluate the ability of our model in generating medical report in Chinese, we collect Chinese image-report pairs in real clinical scenarios to construct a test dataset covering brain, chest, spine, abdomen and pelvis from the hospital.

Visual Question Answering and Diagnosis
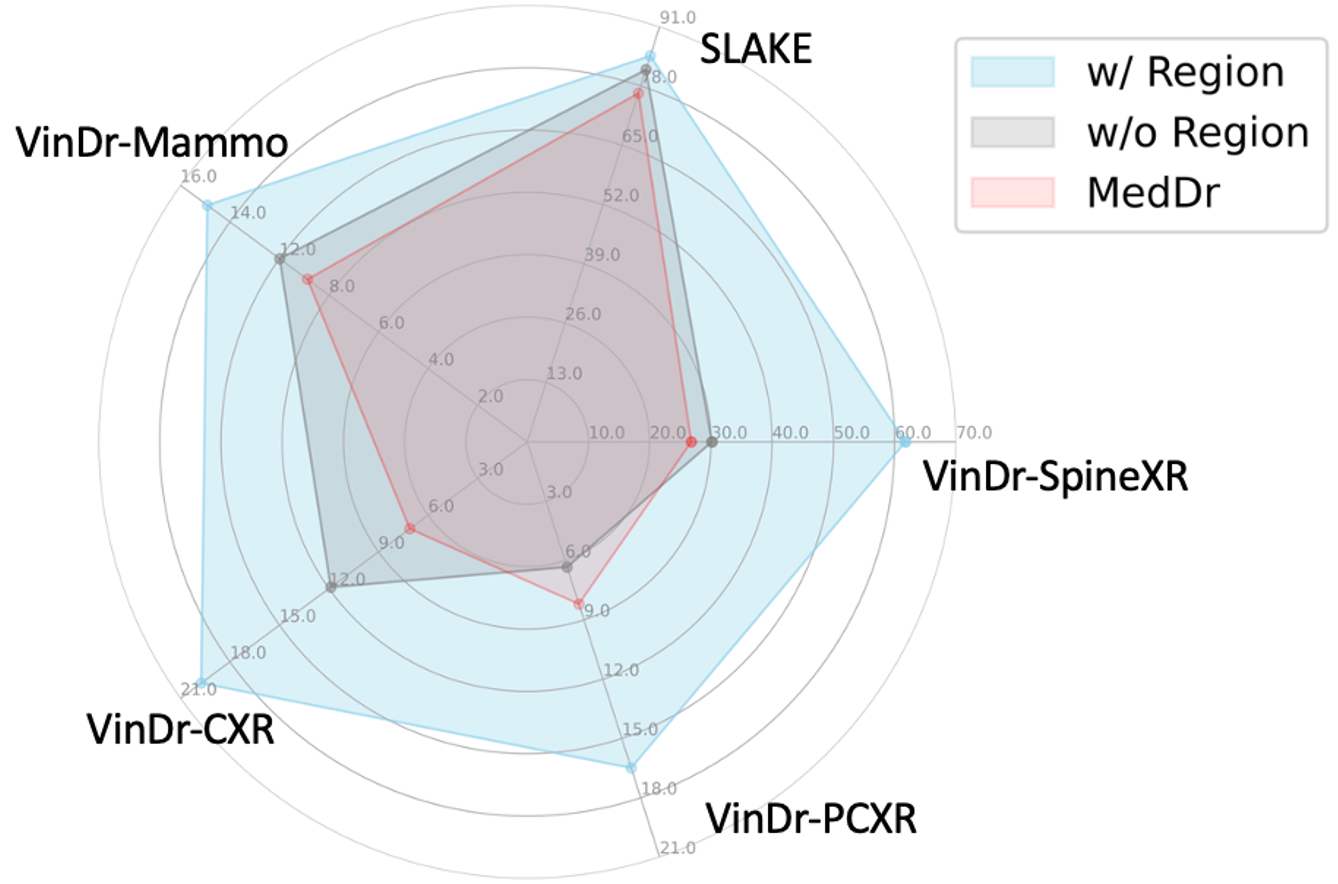
We demonstrate the results on medical VQA benchmark SLAKE, and disease diagnosis benmarks including VinDr series datasets. To further enhance the model's focus on disease lesions, we employ Regional CoT (w/ Region). The improved results indicate that incorporating regional information assists medical MLLMs to concentrate on specific regions.
MedRegA on Region-Centric Tasks
Region-Centric tasks are defined from three perspectives: (1) Region-to-Text Identification, where the model outputs the name of the specified region; (2) Text-to-Region Detection, where the model detects the area of the given organ or anomaly; (3) Grounded Report Generation, where the model generates a report for the medical scan, aligning each description with the corresponding region.
Region-to-Text Identification
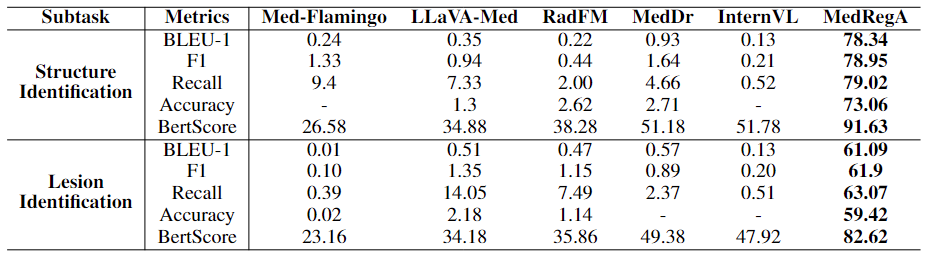
We categorize the task into (1) structure identification for identifying anatomies such as structures within the brain, heart, lung, abdomen or spine, and (2) lesion identification focusing on abnormalities like tumors and cancers. The model demonstrates a stronger capability of identifying body structures compared to lesions, possibly because anatomies tend to be larger, whereas lesions are subtler and exhibit more variation in shape.
Text-to-Region Detection
We classify the task into four categories according to the number of detected objects and the number of regions per object: single-object single-region, single-object multi-region, multi-object single-region, and multi-object multi-region.

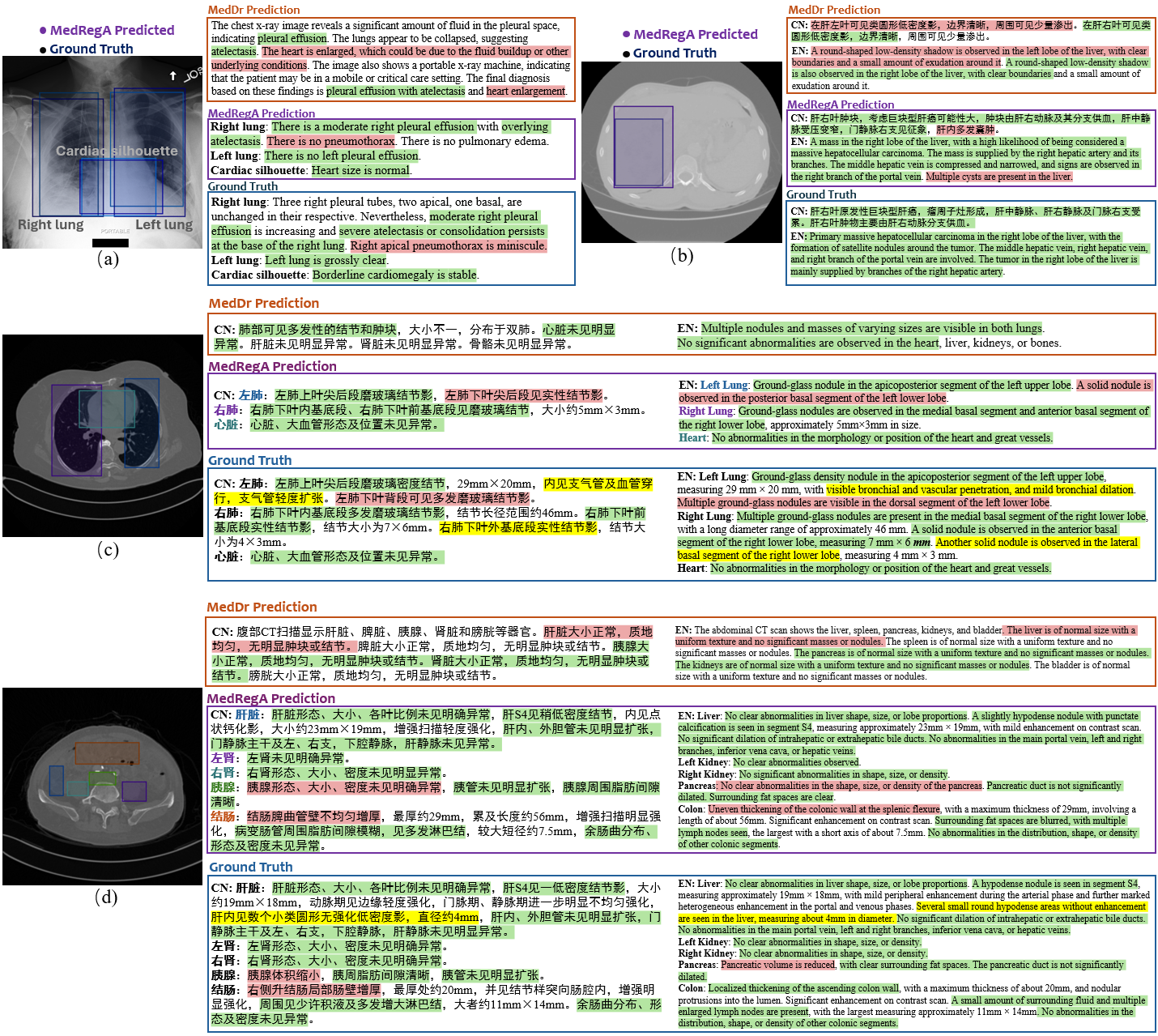
Grounded Report Generation
We exemplify the output of MedRegA for the grounded report generation task below.